A Short and Sweet Guide to Numerai on Google Colab using RapidsAI
Do you like competition? Do you like Data Science? Do you like Crypto? Well, I have an exciting distraction for you called Numerai. Hopefully, in this guide I can tell you some about this project, alongside giving you a template to get started in Google Colab.
Part 1: The Why and What
(You can just skip to Part 2 for the Actual Code.)
What is Numerai?
It is the self-proclaimed hardest data Science competition in the world, but lucky for you; I am here to make it just a tiny bit easier. Every week (and now every day) Numerai releases a dataset of eras, features, and prediction targets. You do not know what the features are or what they represent; you don't know what the target represents; however it is your job to create the best possible model to get from feature to target. Now you may be thinking, if you don’t know the features, how do you know if you are doing well? What are you measured on to score your model? So there is:
Correlation: There is an apparent correlation to the target, which is pretty straightforward.
Meta Model Contribution: In summary, this is how "Unique" your model is. Numerai needs to incentivize different solutions rather than having thousands of the same model with a high correlation which helps the resiliency of the overall model. Measuring uniqueness means that your typical Dense NN or XGBoost won't do very well in this case without custom optimization functions or feature preprocessing (which is what I focus on) https://docs.numer.ai/tournament/metamodel-contribution
Feature Neutral Correlation: This measures how much your model relies on a wide set of features, so Numeari gets better coverage overall on all features. If your model relies on a small set of features, it is more susceptible to variable performance. https://docs.numer.ai/tournament/feature-neutral-correlation
True Contribution: A weighted score of how much your model contributed to the performance of the overall model. A very high-level summary is that TC is the feedback on the overall performance of each signal. See more here: https://docs.numer.ai/tournament/true-contribution-tc
The overall purpose of your model is to be used in conjunction with others for Numerai, the hedge fund, to trade on without them telling you exactly what signals they are using.
The Process
To participate and start running your model takes a couple of steps. First, you need to go to https://numer.ai/tournament, create an account, and create a new model tracker. This is all you would need to do to participate and have your model ranked.
However, you can also earn crypto called Numerai. To do this, you must buy Numerai on an exchange like Coinbase and transfer it to your wallet on the Numerai site. That Numerai then must be staked on a model. Once staked, you can get a payout based on how well your model does and multipliers set by you that emphasize Correlation and True Contribution. For example, you can 0.5x Correlation and 3x True Contribution if you have a unique model that may not perform as well correlation-wise. But be careful; the larger the multiplier, the more you could lose if your model performs poorly. Luckily you can make many models without a stake and see how they perform weekly, and then when you know which one has good performance put your stake there.
After this is all set up, every week you download the tournament data set, run it through the model, and submit a CSV of predictions. Your predictions are then scored over four weeks, and a payout is determined by how well your model did after the fourth week. You continue to do this every week and hopefully can earn some Numerai to sell on Coinbase or restake in your model.
What's in it for me? What does Numeari get out of this?
In reality, this seems suspicious, right? I join this tournament and just get paid like that. What's in it for Numerai? Well, they are a Hedge Fund that trades based on everyone’s models and has (Two?) Funds in which you can join (If you have a couple million to invest). So they get to make real money, while I get unusable coins. In that sense, it’s kind of exploitative. Still, I find it fun and an excellent way to get some practice doing a purely statistical view of data analytics since you are hidden from the underlying feature meaning. That being said, last week, I made about $25, which buys my Pro subscription which is good enough for me, at least for now.
In my opinion, this is an excellent case where Crypto is well suited. Individuals can be credited for work and contributions that are done to a communal model. Ideally, these coins would have more value, but there are regulations on companies paying you for your work legally. Also, you don't even need to stake coins to participate, so there is not much to lose trying it out.
There’s a lot more to read up on about it on the web that I didn’t just want to rehash here. https://docs.numer.ai/tournament/learn is a great place to start.
Why listen to me and my experience?
I am not going to lie. I was going to be subtle at first, but in reality, I want to brag a little. (It is a competition, after all, =D) I started in early 2021, so Ive been doing this for two years on and off. At first the dataset, while significant, was very manageable. It was easy to work worth on Google Colab without your session crashing so that's primarily where I worked. I was consistent for a year and managed to get to number one on the leaderboard in correlation for a couple of weeks. You can actually see me in their intro video on their docs site:
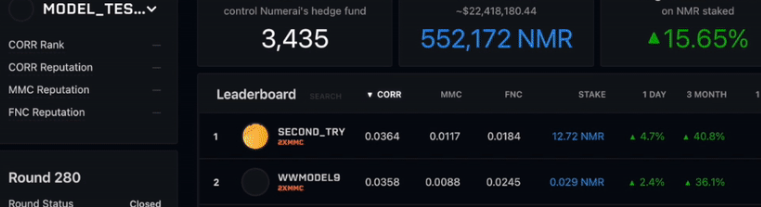
I also got a bunch of “medals” which the top models get every week : 3x Top 1% Correlation,
1x Top 5% TC, 2x Top 5% Correlation, 3x Top 5% MMC
7x Top 15% TC, 15x Top 5% Correlation, 8x Top 15% MMC
But I just want to emphasize how I did this using Google Colab Pro and some basic feature manipulation and PCA with XGBoost. So doing well depends on your models rather than how much pure computing power you can access.
Why is it Hard?
Now I was number one for a couple of weeks. What Happened? Well, they came out with the "Big" Data set, which increased the data set greatly.
See their post here: https://forum.numer.ai/t/super-massive-data-release-deep-dive/4053
The data set grew by 3x Features, 20x Targets, and even more Eras which immediately crashed my Google Colab Sheet, my computer, and many web service instances I tried. The dataset for the problem became significant enough that one had to think about where the data is and just how much of it you used. This was a wake-up call that the feature analysis I did and the model I made could have been more scalable.
At this point, getting it done using Google Colab was not trivial because loading all of the data or training the model crashed even high-RAM instances. Also, getting Rapids AI to work correctly took some time, but I came back, figured it out, and got it working in Colab again (after a short stint trying to use web services). In Part 2, I will show you the framework of how to set this all up in Google Colab and manage the data so it won't crash in your Pro instance using RapidsAI
Part 2: The How (in Google Colab using RapidsAI)
This original base sheet was made by combining a RapidsAI Google Colab Sheet with a Numerai Template sheet. The Rapids AI package is used to easily put data on the GPU and do operations there, as having the extra 12+ GB of space on the GPU helps significantly in getting around “Out of RAM” crashes.
From this base sheet, there are a lot of modifications around where data goes, is worked on, and is deleted to try and squeeze the most out of the RAM and GPU Memory usage of the Google Sheet. It also includes how I reduce the feature set to allow for more significant models and optional PCA code, which can be used if the final XGBoost model is too large to operate on.
There are places like the main training loop where saving the model every cycle for a backup in case the sheet crashes and runs out of RAM.
This can also be used as a general outline for any model. NN, Boost, Regression, etc. Only the model portion would need to be modified, as a lot of the surrounding code deals with the setup and movement of data.
What is RapidsAI?
In this use case it is mainly used to get the cuPy, cuDF packages which are used to get data onto the GPU for processing and training. These packages have a lot of dependencies that need to be installed so it is easier to get the whole package than to get them to run individually. Since this dataset is so large, the more space for memory, the better. These packages work the same way as NumPy and Pandas, except cuDF can store data on GPUs and cuPy does operations on GPUs.
In reality, this package contains a whole lot more than that, like multi-GPU coordination and analysis packages, and I would recommend learning about it here: https://rapids.ai/.
Getting Your Space Setup
Make sure you go to Edit > Notebook Settings and set
Hardware Accelerator as GPU
Runtime Shape as High RAM
# This get the RAPIDS-Colab install files and test check your GPU. Run this and the next cell only.
# Please read the output of this cell.
# If your Colab Instance is not RAPIDS compatible, it will warn you and give you remediation steps.
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git
!python rapidsai-csp-utils/colab/env-check.py
# Read in the file
with open('rapidsai-csp-utils/colab/install_rapids.py', 'r') as file :
filedata = file.read()
# Replace the target string
filedata = filedata.replace('3.7', '3.8')
filedata = filedata.replace('21.12', '22.10')
# Write the file out again
with open('rapidsai-csp-utils/colab/install_rapids.py', 'w') as file:
file.write(filedata)
Note: All text will refer to the code above it.
Above, we do two things. First, we download the Rapids AI scripts from git, and then we replace the versioning of a) the python version and b) the RapidsAI version. I did try many of the alternative ways to modify the Google Colab Python version with success; however, when that is done, the next couple of steps typically fail. So I just updated the version manually in the script to the one Google Colab is currently using and the corresponding Rapids AI version. ( See https://rapids.ai/ for version info )
# This will update the Colab environment and restart the kernel. Don't run the next cell until you see the session crash. !bash rapidsai-csp-utils/colab/update_gcc.sh import os os._exit(00)
This is code to update the gcc version.
# you can now run the rest of the cells as normal import condacolab condacolab.check()
This will install condalab which allows for conda commands inside Google Colab.
# Installing RAPIDS is now 'python rapidsai-csp-utils/colab/install_rapids.py <release> <packages>' # The <release> options are 'stable' and 'nightly'. Leaving it blank or adding any other words will default to stable. !python rapidsai-csp-utils/colab/install_rapids.py stable import os os.environ['NUMBAPRO_NVVM'] = '/usr/local/cuda/nvvm/lib64/libnvvm.so' os.environ['NUMBAPRO_LIBDEVICE'] = '/usr/local/cuda/nvvm/libdevice/' os.environ['CONDA_PREFIX'] = '/usr/local'
Next, we install the RAPIDs AI packages. This will take about fifteen minutes.
Note: Above will NOT have to be rerun if your sheet crashes. Only run after this point if your sheet crashes.
!pip install sklearn numerapi halo pandas
import cudf
import dask_cudf
from halo import Halo
from numerapi import NumerAPI
from pathlib import Path
import cuml
import gc
from numerapi import NumerAPI
import numpy as np; print('numpy Version:', np.__version__)
import pandas as pd; print('pandas Version:', pd.__version__)
from cuml import make_regression, train_test_split
from cuml.metrics.regression import r2_score
import cupy
import seaborn as sns
from scipy.stats import ks_2samp
from scipy import stats
import matplotlib.pyplot as plt
from cuml import PCA
from cuml.decomposition import PCA
import xgboost as xgb; print('XGBoost Version:', xgb.__version__)
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score, KFold
Install and Import a bunch of libraries for future use.
google_drive_path = "/content/drive/My Drive/{your directory}"
from google.colab import drive
drive.mount('/content/drive')
Mount a Google Drive to be able to run sheet and have results saved automatically.
Importing and Setting up the Data
napi = NumerAPI()
spinner = Halo(text='', spinner='dots')
current_round = napi.get_current_round(tournament=8) # tournament 8 is the primary Numerai Tournament
# read in all of the new datas
# tournament data and example predictions change every week so we specify the round in their names
# training and validation data only change periodically, so no need to download them over again every single week
napi.download_dataset("numerai_training_data.parquet", "numerai_training_data.parquet")
napi.download_dataset("numerai_tournament_data.parquet", f"numerai_tournament_data_{current_round}.parquet")
napi.download_dataset("numerai_validation_data.parquet", f"numerai_validation_data.parquet")
napi.download_dataset("example_predictions.parquet", f"example_predictions_{current_round}.parquet")
napi.download_dataset("example_validation_predictions.parquet", "example_validation_predictions.parquet")
spinner.start('Reading parquet data')
training_data = pd.read_parquet('numerai_training_data.parquet')
#tournament_data = pd.read_parquet(f'numerai_tournament_data_{current_round}.parquet')
validation_data = pd.read_parquet('numerai_validation_data.parquet')
#example_preds = cudf.read_parquet(f'example_predictions_{current_round}.parquet')
#validation_preds = cudf.read_parquet('example_validation_predictions.parquet')
spinner.succeed()
Here we download all of the data, however, you may see we only load the training and validation data for now. These sets contain the data used to build the model so once the model is built these objects will be deleted and the next sets of data will be loaded.
feature_cols = [c for c in training_data if c.startswith("feature_")]
training_data_gpu = cudf.DataFrame(training_data.iloc[::4, :])
validation_data_gpu = cudf.DataFrame(validation_data.iloc[::4, :])
Get the list of feature columns and then load two objects into GPU memory using cudf:
Training Data with Every 4th Line
Validation Data with Every 4th Line
Every 4th line is to reduce the amount of data to be worked on and, in addition, is not needed as the data includes the four rounds used to evaluate the final submission. Using the 4th week is sufficient sampling to not lose too much information.
len(feature_cols)
Get a base of how many features exist in the original data set. ( Should be over 1k)
Feature Selection
Y = np.array(training_data_gpu['target'].values.get())
signifigant_features = []
statistics_array = []
for col in feature_cols:
X = np.array(training_data_gpu[col].values.get())
statistic, pvalue = stats.pearsonr(X, Y)
if (pvalue < 0.01) :
signifigant_features.append(col)
statistics_array.append(statistic)
I go through each feature and see if it is significantly related to the target. If it’s below a specific p-value, I store it. The idea here is to reduce dimensionality as much as possible while keeping the most significant features. This could hurt us when evaluated for feature exposure, however.
In addition, I used to look for features that were autocorrelated with one another and drop one. I am still working on a viable way to do that with this larger dataset.
len(signifigant_features)
Here we just check how many features are left. (Usually about 450)
training_data_gpu[signifigant_features] = training_data_gpu[signifigant_features] / 4 validation_data_gpu[signifigant_features] = validation_data_gpu[signifigant_features] / 4 #### Use below if PCA is used. # define transform pca = PCA(n_components=250) # prepare transform on dataset pca.fit(training_data_gpu[signifigant_features]) # apply transform to dataset X_train = pca.transform(training_data_gpu[signifigant_features]) X_validation = pca.transform(validation_data_gpu[signifigant_features]) #### Use below if PCA is not used. X_train = training_data_gpu[signifigant_features] X_validation = validation_data_gpu[signifigant_features]
If you would want to do PCA to reduce dimensionality further there is an option to do so. This is a quick way to reduce the size of your model further in case you are still running out of RAM. Make sure to keep the divide by 4 even if you are not using PCA as this is a quick and easy way to normalize data to be between 0 and 1.
Model Setup and Training
y_train = training_data_gpu["target"] y_validation = validation_data_gpu["target"]
Here we make the objects that contain Y values for the model.
!nvidia-smi
I use this command to check on the status of how much memory is being used on the GPU.
dtrain = xgb.DMatrix(X_train, label=y_train)
dvalidation = xgb.DMatrix(X_validation, label=y_validation)
# instantiate params
params = {}
# general params
general_params = {'silent': 0}
params.update(general_params)
# booster params
n_gpus = 1
booster_params = {}
if n_gpus != 0:
booster_params['tree_method'] = 'gpu_hist'
booster_params['n_gpus'] = n_gpus
booster_params['booster'] = 'gbtree'
booster_params['sampling_method']= 'gradient_based'
booster_params['learning_rate']= .005
booster_params['gamma']= .01
booster_params['max_depth']= 6
booster_params['min_child_weight']= .05
booster_params['subsample']= 0.5
booster_params['colsample_bytree']= 0.5
booster_params['num_parallel_tree']= 6
booster_params['n_estimators']= 500
params.update(booster_params)
emetric = 'rmse'
# learning task params
learning_task_params = {'eval_metric': emetric, 'objective': 'reg:squarederror'}
params.update(learning_task_params)
Here we set up some parameters. I would recommend setting up and using your hyperparameter tuning scheme of choice. This also depends a lot on what model you are using.
Just to note, above is slightly off from the parameters I use, but they are ballpark where to start your search. Also, you can try ‘auc’' as the emetric which sometimes has a better ability to show if the model is improving, but again it depends a lot on the model you choose to use.
# model training settings evallist = [(dvalidation, 'validation'), (dtrain, 'train')] num_round = 25
More parameter setting.
del(training_data)
Delete some data as it is not needed anymore.
%%time
results = {}
train_score = []
val_score = []
bst = xgb.train(params, dtrain, 1, evallist, evals_result=results)
bst.save_model("model.ubj")
del(bst)
# Replace 15 with how many training cycles you would want to do
for i in range(1,15):
results = {}
gc.collect()
print("/============================= " + str(i))
bst = xgb.Booster()
bst.load_model("model.ubj")
bst = xgb.train(params, dtrain, num_round, evallist, xgb_model=bst, evals_result=results)
train_score.append(results["train"][emetric][num_round-1])
val_score.append(results["validation"][emetric][num_round-1])
bst.save_model("model.ubj")
del(results)
del(bst)
Here is the main training loop of the model. An initial run is made to set up the loop, but then the loop goes;
Garbage Collect
Load Model
Train model for num_rounds
Collect Scores
Save Model
Delete Results
This loop is used mainly to have checkpoints for the model, but I’ve had some success with the model having less of a memory footprint inside the GPU when saving/loading the model. In many cases, this will be where the instance will run out of RAM, and in that case the model has to be made smaller through less features, less number of trees, fewer estimators, and/or fewer max_depth.
bst = xgb.Booster()
bst.load_model("model.ubj")
Load the latest saved model.
import matplotlib.pyplot as plt
plt.title("Train Results")
ax = plt.gca()
ax.axes.xaxis.set_ticks([])
plt.plot(train_score, color="red")
plt.plot(val_score, color="blue")
plt.ylim([.45, .7])
plt.show()
Plot the results of the train and validation scores. I use this to tune how many rounds are needed before over training occurs.
Run on Validation and Tournament Data for Submission
del(validation_data_gpu) del(training_data_gpu) validation_data_gpu = cudf.DataFrame(validation_data) # If PCA is Used #dvalidationX = xgb.DMatrix(pca.transform(validation_data_gpu[signifigant_features])) validation_data_gpu[signifigant_features] = validation_data_gpu[signifigant_features] / 4 dvalidationX = xgb.DMatrix(validation_data_gpu[signifigant_features])
Delete unneeded structures and then load the validation data onto the GPU. Numerai has the ability to have a validation set of predictions where you load them into the site, and more advanced metrics will come back up.
spinner.start('Predicting on latest data')
model_name = "newModel"
# double check the feature that the model expects vs what is available
# this prevents our pipeline from failing if Numerai adds more data and we don't have time to retrain!
model_expected_features = signifigant_features
if set(model_expected_features) != set(feature_cols):
print(f"New features are available! Might want to retrain model {model_name}.")
validation_data.loc[:, f"preds_{model_name}"] = bst.predict(dvalidationX)
spinner.succeed()
Run the model to get predictions on the validation set.
from datetime import datetime now = datetime.now()
Use date time to give unique save file names.
model_to_submit = f"preds_{model_name}"
col = "id"
v_pred = pd.DataFrame([],columns=['id','prediction'])
v_pred["id"] = validation_data.index
v_pred = v_pred.set_index("id")
date_time = now.strftime("%m_%d_%Y__%H_%M_%S")
v_pred["prediction"] = validation_data[model_to_submit]
v_pred["prediction"].to_csv(f"validation_predictionsn_{date_time}.csv")
v_pred["prediction"].to_csv(google_drive_path+f"validation_predictionsb_{date_time}.csv")
Save validation results to a CSV and put in Google Drive.
del(validation_data_gpu)
del(validation_data)
del(dvalidationX)
tournament_data = pd.read_parquet(f'numerai_tournament_data_{current_round}.parquet')
# If PCA is Used
#dtournamentX = xgb.DMatrix(pca.transform(tournament_data_gpu[signifigant_features]))
tournament_data[signifigant_features] = tournament_data[signifigant_features] / 4
dtournamentX = xgb.DMatrix(tournament_data[signifigant_features])
Delete unneeded structures and then load the tournament data into RAM.
spinner.start('Predicting on latest data')
model_name = "newModel"
# double check the feature that the model expects vs what is available
# this prevents our pipeline from failing if Numerai adds more data and we don't have time to retrain!
model_expected_features = signifigant_features
if set(model_expected_features) != set(feature_cols):
print(f"New features are available! Might want to retrain model {model_name}.")
tournament_data.loc[:, f"preds_{model_name}"] = bst.predict(dtournamentX)
spinner.succeed()
Run the model on the tournament data.
model_to_submit = f"preds_{model_name}"
col = "id"
t_pred = pd.DataFrame([],columns=['id','prediction'])
t_pred["id"] = tournament_data.index
t_pred = t_pred.set_index("id")
t_pred["prediction"] = tournament_data[model_to_submit].values
t_pred["prediction"].to_csv(google_drive_path+f"tournament_predictionsn_{date_time}.csv")
t_pred["prediction"].to_csv(f"tournament_predictionsb_{date_time}.csv")
Save validation results to a CSV and put in Google Drive.
Submit Results
Every Saturday about midday the new data is released. You then have to run the above and submit by midday Monday.
Note: This can be automated but I am too lazy. Might make an update to show how that can be done.
Download the tournement_predictions and validation_predictions CSV from the Google Drive.
Then on the main page for your model, upload the tournament CSV to the “Upload Predictions” and validation CSV to the “Diagnostics Tool”. The Diagnostics Tool gives you a lot of feedback and is where you can find correlation, feature exposure, and meta-model contribution scores.
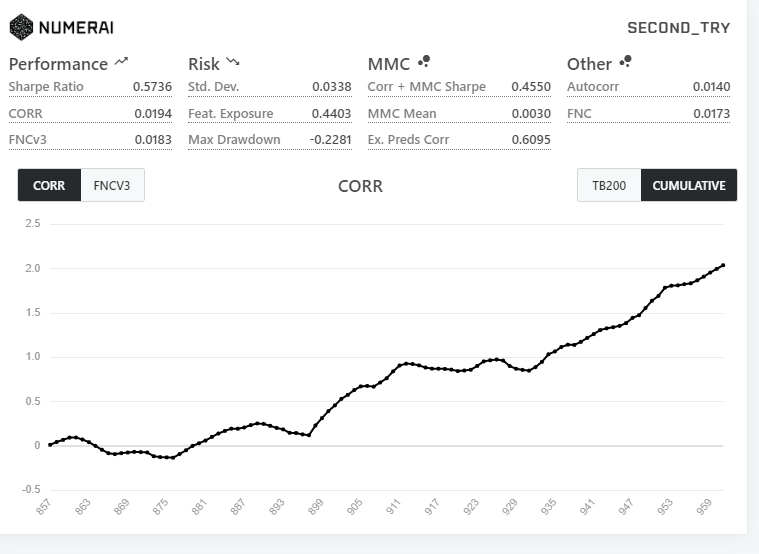
Conclusion
With above, you can have a plug-and-play setup for submitting models every week and also have something to experiment with your own models. It took me a couple of weeks to really balance all of the parameters to not overtrain, keep a model that fits into memory, and has a high correlation. But overall just wanted to share a cool corner of crypto and data science that is interesting to play with.